In every application, the install directory is set to defaults such as /var, /opt, or /usr/local (even the / root directory) for data and logs. This is fine for testing purposes. However, for production use, especially when the application becomes really active, those data and log directories can be big. An alternate storage location, such as LVM or xfs, will be needed that can re-sized for future expansion.
In this example, let’s perform the requirement to move Docker’s default directory into a separate xfs formatted disk. For Red Hat Enterprise Linux 7 installation, this Docker setup is off the RPM repository. The default is /var/lib/docker for the data files. In order to change the path into somewhere else, for example /disk2/docker, first change the /etc/sysconfig/docker file to reflect the change:
Move the files from /var/lib/docker into the new /disk2/docker directory. Since SELinux is enabled for production environment, Docker will need the permission to write into the new directory:
semanage fcontext -a -s system_u -t container_var_lib_t ‘/disk2/docker(/.)?’
semanage fcontext -a -s system_u -t container_share_t ‘/disk2/docker/./config.env’
semanage fcontext -a -s system_u -t container_file_t ‘/disk2/docker/vfs(/.)?’semanage fcontext -a -s system_u -t container_share_t ‘/disk2/docker/init(/.)?’
semanage fcontext -a -s system_u -t container_share_t ‘/disk2/docker/overlay(/.)?’semanage fcontext -a -s system_u -t container_share_t ‘/disk2/docker/overlay2(/.)?’
semanage fcontext -a -s system_u -t container_share_t ‘/disk2/docker/containers/./hosts’semanage fcontext -a -s system_u -t container_log_t ‘/disk2/docker/containers/./..log’
semanage fcontext -a -s system_u -t container_share_t ‘/disk2/docker/containers/./hostname’
And finally, restore the file context for /disk2/docker:
restorecon -R /disk2/docker
Start up the Docker service again, and the environment is now ready to use!
Ever since the GSA been decommissioned, there seems to be one clear winner as a replacement: Elasticsearch. The search engine software is also quite powerful and versatile. It can be adapted to do customized site searches, or use the ready-made tools to ingest logs from Apache web servers, or others like systems data, network packets, and even Oracle databases. Best of all, it’s based on open-source software (Apache Lucene) and the functional basic version is free to use!
Naturally, as part of a sysadmin job, being able to analyze logs and have it searchable and visualized (in Kibana) will make the job easier. For Enterprise environments that use JBOSS EAP as an app container, one can use Elasticsearch to parse through the logs, both historical and in real-time. The tools are:
From the search engine itself, to the individual tools, there are a lot of information on the Elastic site on how to configure and run them, including examples. It is assumed Elasticsearch and Kibana have been configured and running, and Logstash and Filebeat have been setup. The purpose of this post is only to show the possibility of parsing through JBOSS logs.
When JBOSS logs are enabled, use Filebeat to read through all of the access_log files using a wildcard. Filebeat is a lightweight (written in Go) application that can sit on the JBOSS or Web servers, and not interfere with the current operations. It’s ideal for production environments. The filebeat.yml file looks something like this:
Filebeat has a nifty feature that continues to read a log file as it is appended. However, be warned, if the log file gets truncated (deleted or re-written), then Filebeat may erroneously send partial messages to Logstash, and will cause parsing failures.
In Logstash, all the Filebeat input will now need to parsed for the relevant data to be ingested into Elasticsearch. This is the heart of the ingestion process, as Logstash is the place where the data transformation is happening. A configuration file in the /etc/logstash/conf.d directory looks like this:
input {
beats {
port => 5044
}
}
filter {
if "beats_input_codec_plain_applied" in [tags] {
mutate {
remove_tag => ["beats_input_codec_plain_applied"]
}
}
grok {
match => {
"message" => '%{IPORHOST:clientip} %{USER:ident} %{USER:auth} [%{HTTPDATE:timestamp}] "%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response:int} (?:-|%{NUMBER:bytes:int}) (?:-|%{NUMBER:perf:float})'
}
}
date {
match => [ "timestamp", "dd/MMM/YYYY:HH:mm:ss Z" ]
locale => en
remove_field => "timestamp"
}
mutate {
remove_field => [ "message", "@version", "[beat][version]", "[beat][name]", "[beat][hostname]" ]
}
}
output {
if "support" in [tags] {
elasticsearch {
hosts => ["elasticsearch-hostname:9200"]
manage_template => false
index => "jbosslogs-support-%{+YYYY.MM.dd}"
}
}
Logstash listens on port 5044, on the same (or separate) server as Elasticsearch. When ingesting a lot of data, both Logstash and Elasticsearch engines (Java based apps) will consume quite a bit of CPU and Memory, so it’s a good idea to separate them.
In this example, a JBOSS access_log entry is something like:
The most important number is the last field, which is a floating-point value for the URL execution time (in seconds). It’s assigned to a field name “perf”, as in performance. Kibana can be used to gather/visualize the perf values and see if there’s any issue with the JBOSS application.
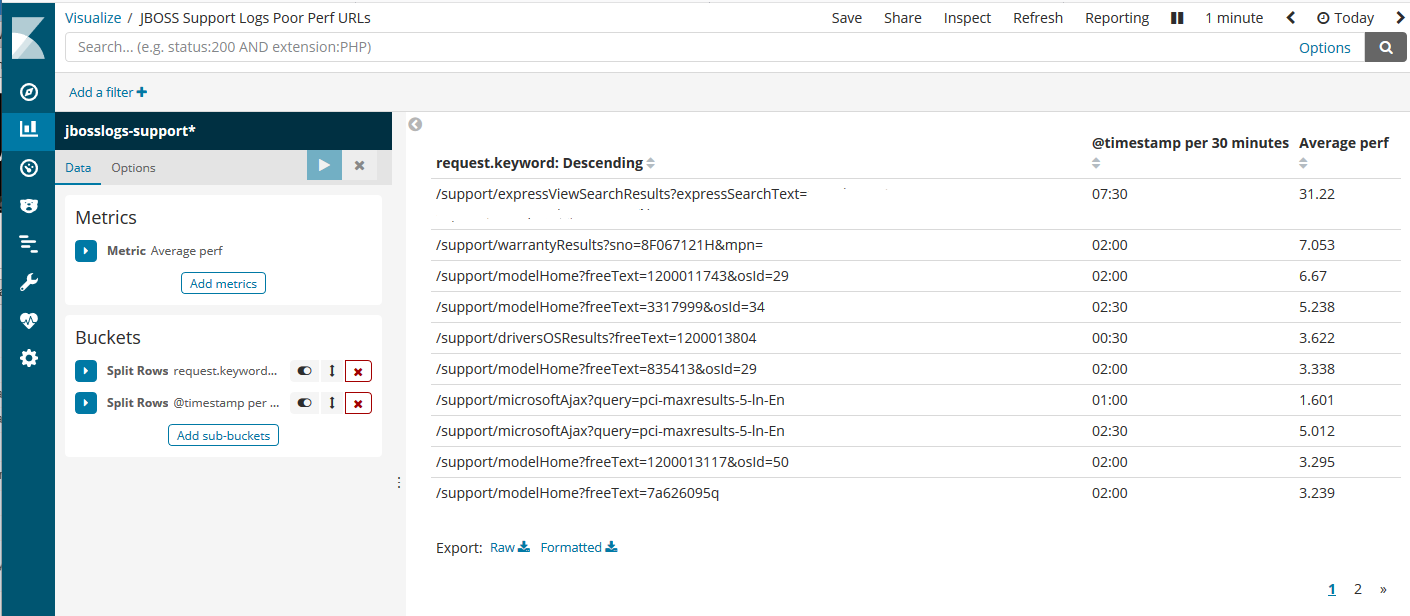
Kibana Snapshot
The above screenshot indicates the top few URLs with average performance times above 3 seconds. The timestamp column shows the time it happened during the timespan selected (in this example, “today”). Then just zoom into the specific time and troubleshoot the Java app, accordingly.
This is just one way to dive into the JBOSS logs using Elasticsearch and Kibana. An Elastic engineer can spend hours creating and tweaking this setup in order to get the most of the available data. At least the tools are friendly enough to configure, with plenty of documentation available on their website. The software has been around long enough, with plenty of community support, that searching the forums (via Google) can give helpful hints for the customization effort. In general, this is an impressive (and fun) way to perform log analysis. For the price, it’s quite impressive. No wonder Elastic’s IPO raised over $250 million on the first day! They’re on the right track to be the next hot company with products Enterprise customers can really use.
There’s been a lot of talk lately about Bringing Your Own Device (BYOD) to work. It’s not a new concept. People love their smartphones, tablets, or laptops. They prefer using a particular brand for personal and work. They bring it to work because it’s convenient to carry just one device, and they can be productive with their own.
Traditionally, companies provide their own “certified” devices to retrieve secured Enterprise data. However, it’s difficult to stop employees from transmitting those data somewhere else, either via E-mail, USB drives, or Cloud Storage, potentially enabling others to see them. A strong privacy policy may be enough deterrent – at least in the beginning. As time goes by, employees will get complacent and too comfortable in taking their data everywhere, not realizing the confidential data may be leaked.
As an IT leader, one can imagine the complexity of supporting multiple devices and worries about zero control over securing protected data. Case in point, the biggest early adopter of BYOD was IBM. They learned valuable (and painful) lessons from it. Employees were not aware of insecure apps, not using secure channels to transmit data, and losing their unprotected/unencrypted devices. These security breaches could potentially cost them, or anyone else for that matter, millions of dollars to repair.
So, why is there growing trend to adopt BYOD? In this tough economic condition, company expenses have to be cut aggressively. The most obvious is to stop allocating budget for productivity machines. Having the cost shifted to the employees, it eliminates the need for company’s machines to be stocked, upgraded, and re-stocked.
Employees have also voiced their concern about the lack of productivity using company issued devices, such as a Blackberry, instead of their favorite iPhone or Android phones. It doesn’t make any sense to have a dedicated, company issued, device just to receive e-mails or phone calls for work, and another for personal use. It certainly becomes challenging to carry two devices, especially when an iPhone, for example, is more than enough to handle all of those tasks and be just as productive.
IT leaders are starting to embrace this BYOD trend because solutions are starting to appear, as the concept become widely accepted. Android and iPhone devices are now equipped with additional security to deter data theft or loss. Both Google and Apple are serious about Enterprise adoption and have updated their OS to be more secure. Now, it’s up to the IT leaders to trickle down the information to users on how to secure their devices, according to the companies’ need. Instead of preventing employees to bring their own devices, educate them on how to secure the content of their own devices. As Ronald Reagan would say: “Trust, but verify.” There is a level of trust on both sides, but both must remain vigilant.
It is time to stop believing the myths of bringing-your-own-device to work. BYOD is happening, whether or not IT is ready. It is the “new normal”.