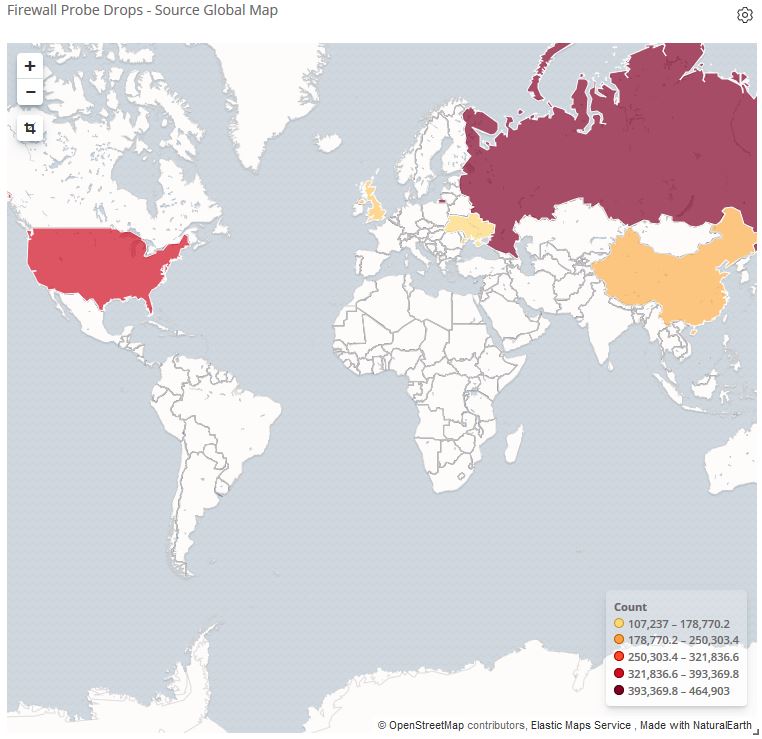
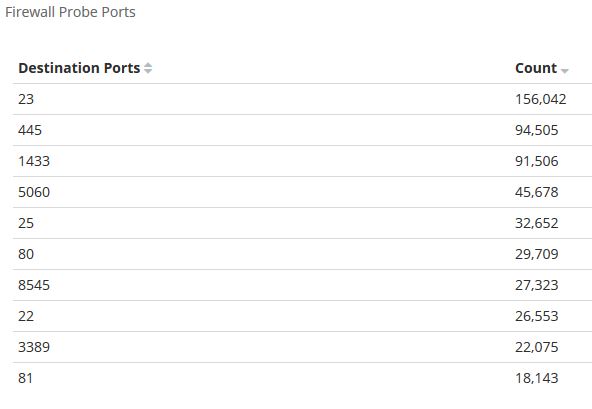
When dealing with indices, it’s inevitable there will be a need to change the mapped fields. For example, in a firewall log, due to default mappings, a field like “RepeatCount” was stored as text instead of integer. To fix this, first write an ingest pipeline (using Kibana) to convert the field from text to integer:
PUT _ingest/pipeline/string-to-long
{
"description": "convert RepeatCount field from string into long",
"processors": [
{
"convert": {
"field": "RepeatCount",
"type": "long",
"ignore_missing": true
}
}
]
}Next, run the POST command reindex the old index into the new one, while running the pipeline for conversion:
POST _reindex
{
"source": {
"index": "fwlogs-2019.02.01"
},
"dest": {
"index": "fwlogs-2019.02.01-v2",
"pipeline": "string-to-long"
}
}If there are multiple indices, it’s recommended to use a shell script to deal with the individual index systematically, such as “fwlogs-2019.02.01”, “fwlogs-2019.02.02”, etc.
#!/bin/sh
# The list of index names in rlist.txt file
LIST=`cat rlist.txt`
for index in $LIST; do
curl -HContent-Type:application/json --user elastic:password -XPOST https://mysearch.domain.net:9200/_reindex?pretty -d'{
"source": {
"index": "'$index'"
},
"dest": {
"index": "'$index'-v2",
"pipeline": "string-to-long"
}
}'
doneFinally, clean up the old indices by deleting them. It’s a temptation to use Kibana to DELETE fwlogs-2019.02*, but beware the new indices have the suffix “-v2” and it will be deleted if the wildcard argument is used. Instead use the shell script to delete based on the names specifically listed in the txt file.
#!/bin/sh
# The list of index names in rlist.txt file
LIST=`cat rlist.txt`
for index in $LIST; do
curl --user elastic:password -XDELETE "https://mysearch.domain.net:9200/$index"
done